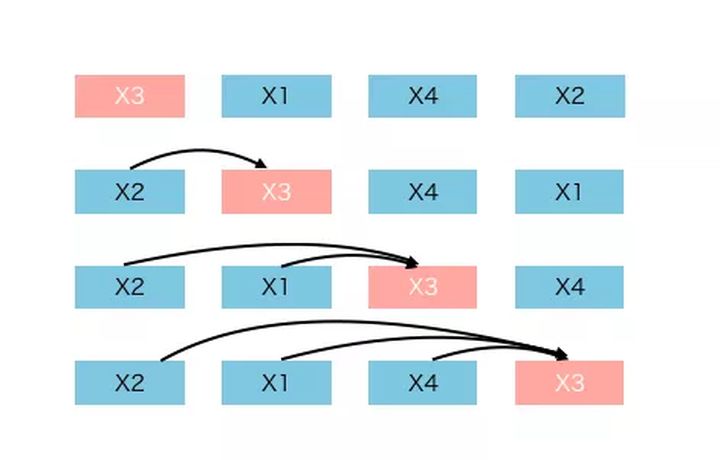
动机
为了研究NLG和NLU,我们必须要了解主流的预处理方法,以便更好的服务下游任务。
预处理语言模型:理论&架构&技巧
2013年,word2vec横空出世。在那个深度学习还未出现,caffe尚未被开发的年代,这个最早的自然语言预处理模型给人工智能带来了一些惊喜,比如【国王-男人=女王-女人】的词类比。当时的人们还不知道这项技术有何用处,受制于当时的硬件条件,在那个岁月静好,网络层很少的年代,word2vec如同种子一般深埋大地。直到14年后,预处理语言模型终于成长为参天大树,并在那个名为BERT的树干之上开花结果,令人眼花缭乱。
独热码
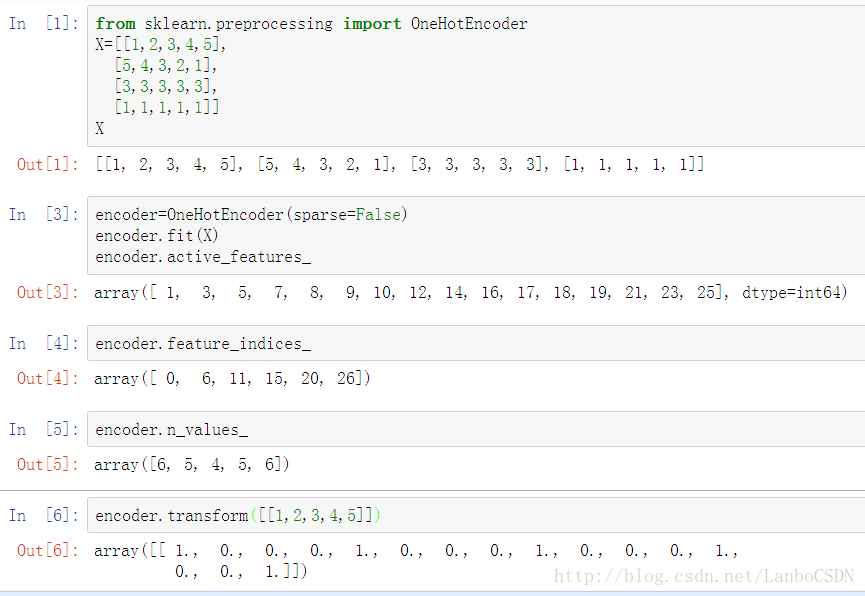
缺点:矩阵太大,而且极为稀疏
共现矩阵
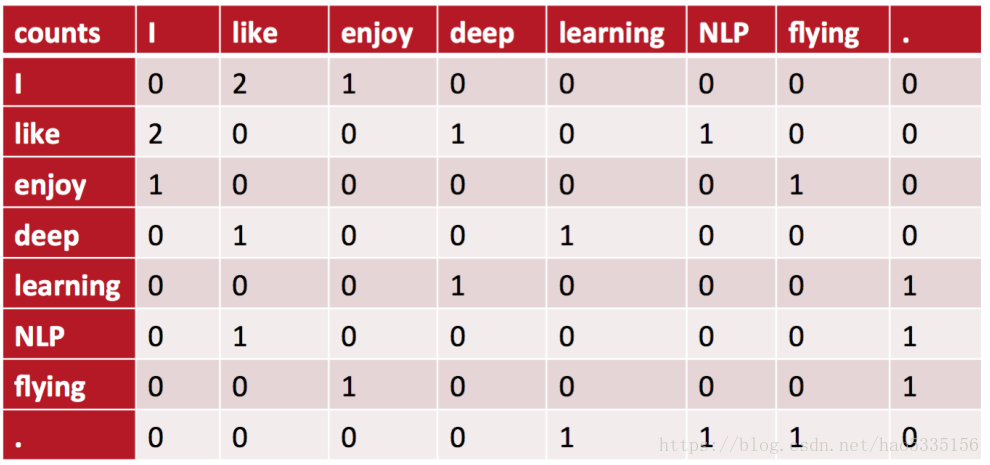
缺点:矩阵太大,而且极为稀疏
【2003年】 NNLM:基于前馈神经网络的 N 元神经语言模型
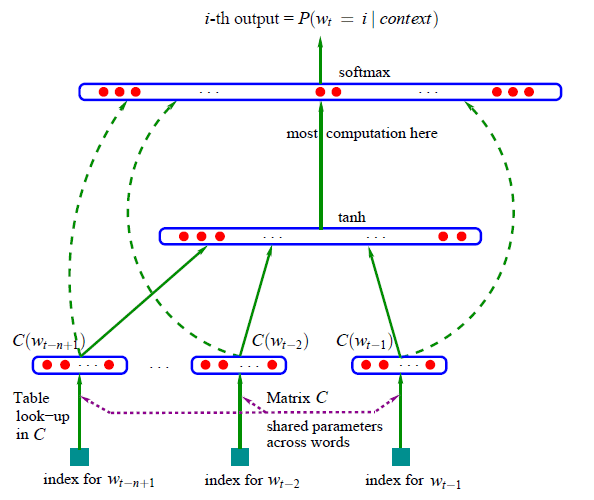
【2013年】 word2vec
作为被大家公认的第一个预处理语言模型()
八卦时间
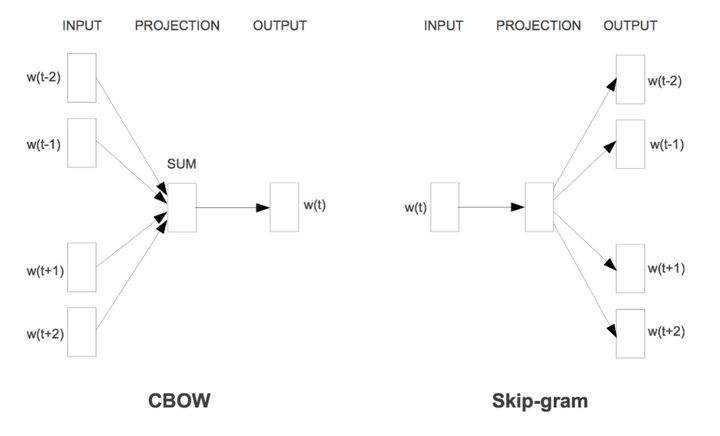
word2vec的主要贡献并不是其结构,因为skip gram(预测+聚类) 和 CBOW(采样+完形填空)在传统方法中也有被用到(比如n元语法),也不是层次化的softmax(Hierarchical Softmax)和 负采样(negative sampling),毕竟这些写不成公式的方法都属于trick。
主要贡献是【词类比】。
首先来解释word2vec中的各项技术:
- CBOW:continuous bag of words 连续词袋模型。可以理解为:用一个固定大小的窗口对语料库进行采样,并对采样后的样本做一个“完形填空”,用窗口中的周围词去预测中心词。
- skip gram:得到了预测到的中心词之后,再反过来用中心词去预测周围的词。从直觉上来说,同一个窗口中的词汇应该在某种程度上更加近似,所以skip gram就有点聚类的味道了。
- Hsoftmax: 可以先看一下softmax的函数图像
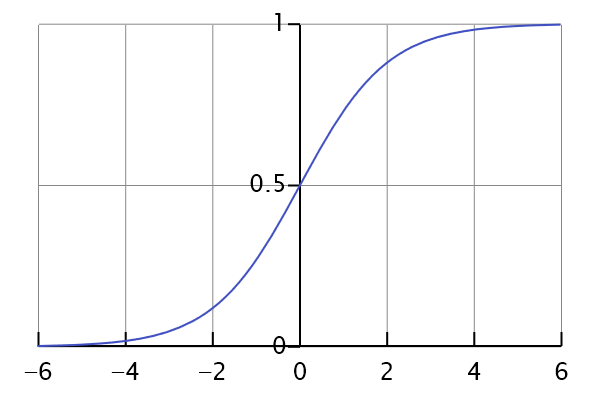 如果直接预测,会分母太大,直接爆炸,因为少说也是大几千的token量。但如果分开来看,每一句都给一个softmax,那就不会产生爆炸,有点像激活函数和BN。
如果直接预测,会分母太大,直接爆炸,因为少说也是大几千的token量。但如果分开来看,每一句都给一个softmax,那就不会产生爆炸,有点像激活函数和BN。 - 负采样:就是预测标签中的一个子集。因为整个标签集太大了,即使是现在的硬件水平做起来也很慢。
那为什么词类比成了word2vec的主要贡献了呢?个人认为是它达到了一个【情理之中,意料之外】的效果。
到目前为止,预训练模型都充满了令人怀念的古早味。那时的NLP三四层是比较正常的,超过十层都属于“巨型结构”。
【2015】Semi-supervised Sequence Learning
可以说是预训练语言模型的开山之作,明确了“pretrain”的概念,提出了预训练模型的“fine-tuning”概念。虽然这篇文章放在今天看来,它的思想已经让我们感到理所当然,它的效果也没有那么地让人感觉惊艳,但是放在那个历史时刻里,它就像一盏明灯,为人们照明了一个方向。
论文的主要内容如下:
- 利用自回归(AR)对一个句子进行逐词预测。
- 利用自编码方法(AE)对句子进行映射再重构。
他们明确提出了,这两种算法可以为接下来的监督学习算法提供 “pretraining step”,换句话说这两种无监督训练得到的参数可以作为接下来有监督学习的模型的起始点,他们发现这样做了以后,可以使后续模型更稳定,泛化得更好,并且经过更少的训练,就能在很多分类任务上得到很不错的结果。
众所周知,RNN模型虽然对时序数据建模很强大,但是因为训练时需要 “back-propagation through time”, 所以训练过程是比较困难的。Dai 和 Le 提出的预训练的方法,可以帮助RNN更好的收敛和泛化,而且在特定业务上不需要额外的标注数据,只需要收集成本很低的无标注的文本。而且这些文本与你的特定业务越相关,效果就会越好,他们认为如此一来,这种做法就支持使用大量的无监督数据来帮助监督任务提高效果,在大量无监督数据上预训练以后只要在少量监督数据上fine-tuning就能获得良好的效果,所以他们给这篇论文取名为 “半监督序列学习”。
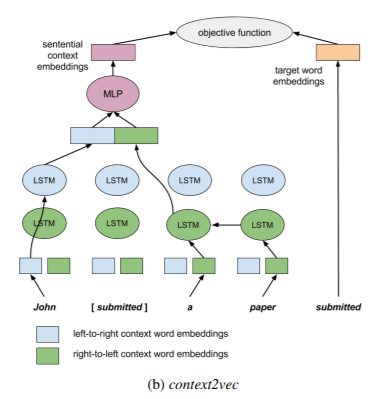
【2016年】context2vec: Learning Generic Context Embedding with Bidirectional LSTM
双向LSTM + mask
这篇文章提出的idea是学习文本中包含上下文信息的embeddings。由于词在不同上下文可以有歧义,相同的指代词也经常在不同上下文中指代不同的实体。所以NLP任务中很重要的就是考虑每个词在其上下文中所应该呈现的向量表达方式。从摘要看,这篇文章的主要贡献,是它使用了双向的LSTM可以从一个比较大的文本语料中,有效地学到了包含上下文信息的embeddings,在很多词义消岐,完形填空的任务上都取得了不低于state-of-the-art的效果。同时他们提到,之前的研究有把上下文的独立embedding收集起来,或是进行简单的平均,而没有一个比较好的机制来优化基于上下文的向量表达。所以,他们提出了context2vec ,一个能够通过双向LSTM学习广泛上下文embedding的非监督的模型。
从这一年之后,NLP进入了大力出奇迹的时代

【2017年】ELMO
更大的双向LSTM。
具体而言,ELMO的底层输入推荐使用已经学好的静态词向量比如Glove等,向上接两层的双向LSTM作为特征提取器,最终以语言模型作为训练任务进行学习。学好之后,每一个词会得到三个向量(底层,第一层拼接LSTM,第二层拼接LSTM),ELMO告诉你只要下游任务用到WordEmbedding的时候,就用产生的三个向量进行加权平均,其中的权重需要在新任务中进行学习。而这种方式也称为Feature-based Pre Training。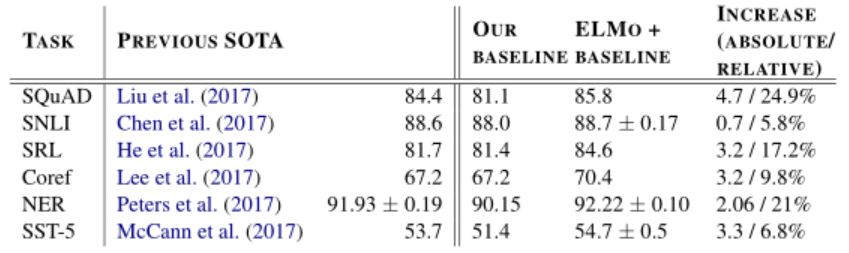
相应的评价指标也都做到了在当时的SOTA,并比其他的高出5-25个百分点。这么好的效果和清晰地思路也使得该论文获得了NAACL2018最佳论文。不过,现在看来ELMO也有缺点,具体而言:
- LSTM抽取特征的能力远弱于Transformer
- 拼接方式双向融合特征融合能力偏弱。
【2018】GPT & BERT
GPT最主要的贡献就是证明了tranformer结构比RNN更好。
除了以ELMO为代表的这种基于特征融合的预训练方法外,NLP里还有一种典型做法,这种做法和图像领域的方式更为契合,我们一般将这种方式成为基于“Fine-tuning”的二阶段训练。
GPT:ImprovingLanguage Understanding by Generative Pre-Training 其实就是Transformer的decoder,一种采用了masked self-attention的训练方式。GPT总结而言有以下几点:
- semi-supervised learning:无监督pre-train+下游有监督fine-tune
- multi-task learning:损失函数为预训练阶段languagemodel目标函数+ λ * 有监督softmax损失
- 12个decoder:masked-attention(12个multi-head+768维)+ point-wise FFN(3072维)+ Adam + warm-up + GELU
BERT刷榜
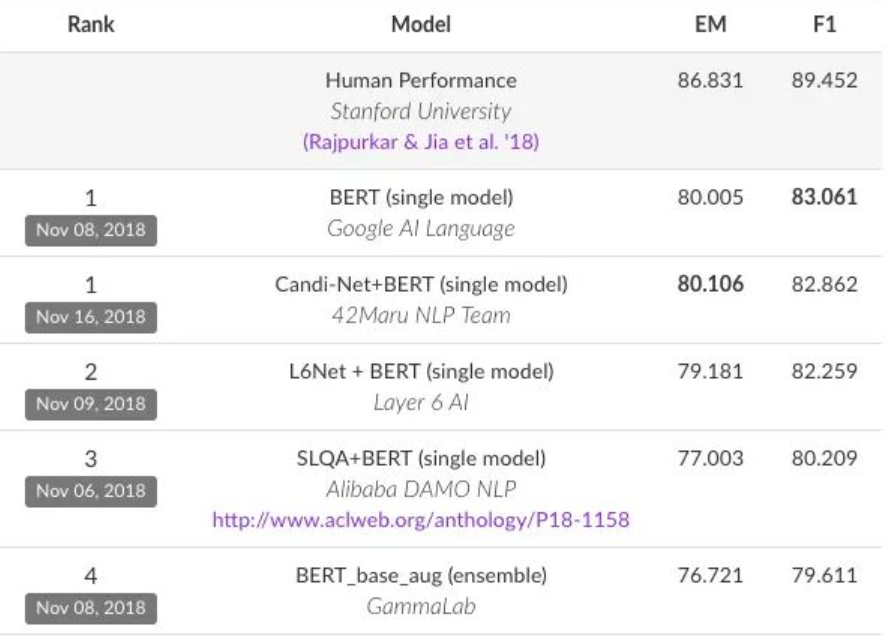
RoBERTa,屠榜神器
- 更大的训练集:16GB-> 160GB
- 更长的训练时间,6W美金训练一次。
- 静态Mask -> 动态Mask
- 去除了NSP
ALBERT
- 词嵌入向量参数的因式分解
- 跨层参数共享 (feed-forward network、attention、all)
- NSP 预训练任务-> Sentence-order prediction (SOP)
- 去掉dropout、LAMB优化器、更大的batch-size
- N-gram mask
ERINE,更加疯狂的mask训练
- Basic-Level Masking:和BERT的方式一致,简单的随机mask单独的单词
- Phrase-Level Masking:对命名实体进行全词Mask,包括人名、地名、机构名等
- Phrase-Level Masking:对短语进行全词的Mask,如 a series of等
- 引入多源数据语料:百科类,新闻资讯类、论坛对话类数据并引入DLM(Dialogue Language Model)来训练模型。
XLNET
本文最后介绍的就是xlnet了。
因为BERT的训练中有mask占位符存在。如果一个原本有4000词的文本,在训练的时候就会变成4001词(至少)。这就会造成三个问题:
- 训练与使用不一致,因为在使用阶段是没有mask占位符的。
- 多出来的mask占位符会影响整体性能。
- mask的训练假设是,被mask掉的词是统计独立,但显然不是。
- 因为BERT的mask占位符在训练阶段有15%,这也就是说,BERT的训练效率只有15%。
xlnet希望解决上述问题。
根据组合数学,一个由n个词汇组成的句子会产生n!个语言模型。xlnet利用了一个巧妙的方式在训练阶段学习到了这n!个语言模型。