写在最前面的逻辑导图
如果看晕了就可以回过头看一下这个,整理思路。
主线剧情
- 句子可以用一个联合概率分布来描述
- 但是联合的不好算,我们用贝叶斯全概率公式改写成条件概率分布
- 条件概率分布是链式的,可以用递归的方法计算
- 自然而然的得到seq2seq结构
- 针对seq2seq的固有问题,提出attention解决方案
- 绕了一圈又突然发现attention就可以直接求解联合分布
- 深度学习的哲学1:不好算的东西都交给神经网络去拟合,我们用attention算法来拟合联合概率分布。
- 深度学习的哲学2:大力出奇迹,如果一层attention不能拟合联合分布,那就叠100层。
- 深度学习的哲学3:能用显卡解决的问题,就不要用算法。几十层attention堆叠的BERT就这么被搞出来了。而且BERT的原理十分简单(相对于传统的机器学习),但是效果又出奇的好,是NLP的里程碑。
- 既然有了求解联合分布的BERT,那么文本生成任务实际上就可以看成是全概率公式的逆向运用,用条件概率(也就是不完整的输入)去求联合分布(完整的文本)
- 整 上 花 活:当我们不再满足于单个句子的联合分布的计算的时候,比如对话或者长文本生成,这时候,针对更长的文本的联合分布的计算,我们就需要用mask方法了。虽然这个方法的名字叫做【掩码】,但实际上它的作用相当于胶水。
什么是文本生成?
文本生成在计算机领域指的是用算法生成可读的文本(让代码说人话),所谓的人话就是自然语言,这东西极其复杂,因此与自然语言相关的任务大都是非常棘手的。
文本生成的局限性
- 模型的自然语言理解和语义分析。
- 长程依赖和全局一致
- 融入知识图谱
以上这三条摘抄自一片综述性文章,都是NLP中的困难问题,当然也是研究的重点方向。
经典的Seq2Seq
 *
* 原理
Seq2Seq模型是一种基于RNN的序列学习模型,其主要的工作原理是求解条件概率。(不要太在意下标,问题不大)
例如给定一个句子:
今天晚上去吃麻辣【】
我们已经给定了“今天晚上去吃麻辣”这几个字符,也就是对应的$x_1$至$x_n$。那么现在,我们的任务就是求解【】内的内容。所以,今天晚上究竟是吃麻辣小龙虾还是麻辣香锅,这个问题就是神经网络所需要解决的重点了。
对应实际的问题,我们可以将公式写成如下形式:
其中,sentence是由$n$个单词组成的有序集合。只有当这些单词有序的时候,整个句子才会产生意义。虽然我们不知道自然语言的结构形式,但至少我们可以从概率的角度先进行考虑:
但问题是上式右边是一个联合分布,求解困难。当然,如果加入一点马尔科夫的思想,这个联合分布讲道理还是可以计算出来的,也确实有这种算法,那就是n元语法:
n元语法((n-gram grammar)建立在马尔可夫模型上的一种概率语法.它通过对自然语言的符号串中n个符号同时出现概率的统计数据来推断句子的结构关系.当n=2时,称为二元语法,当n = 3时,称为三元语法.
我们可以退而求其次,继续将公式改写成如下形式:
这样,我们就得到了一个贝叶斯视角下的句子建模了。上式是计算可行的,其中$n$并非趋近于无穷,因为一个句子总是有结束的时候。甚至当我们不开心的时候可以指定$n=1$,这就对应了一个字的回复。

那么应该如何计算呢?
我们可以递归的计算:先求第一个字的概率,然后将答案作为输入,输入神经网络中再计算第二个字的概率。。。这就是递归神经网络(RNN)了。
随着硬件计算能力的进步,现在的RNN一般都是结合n元语法的思想,每次的输入都是n个字符,然后去求第n+1个字符。
这时候,我们就可以自然而然的得出seq2seq结构了。
seq2seq的结构

究其原因,最主要问题是RNN的长程依赖问题,形象的说就是“记不住”和“记得太死”。当然后来的LSTM和GRU都在一定程度上缓解了这个问题,但还是治标不治本。这里就需要提到一个概念:Exposure Bias
Exposure Bias 是在RNN(递归神经网络)中的一种偏差,即 RNN 在 训练(training) 时接受的标签是真实的值(ground truth input),但测试 (testing) 时却接受自己前一个单元的输出(output)作为本单元的输入(input),这两个setting不一致会导致误差累积error accumulate,误差累积是因为,你在测试的时候,如果前面单元的输出已经是错的,那么你把这个错的输出作为下一单元的输入,那么理所当然就是“一错再错”,造成错误的累积。
Exposure Bias给我的感觉实际上是这样的:
工程师:马冬【梅】
RNN:马什么梅?
工程师:马【冬】梅
RNN:什么冬梅?
工程师:最后一遍,马冬梅,记住了吗?!
RNN:记住了记住了。
工程师:马什么梅?
RNN:马化腾

那有的小朋友就会问了,为啥呢?

为了回答小朋友的这个问题,我们可以设想,如果现在机器预测出了一个【小】字,那你以为最终结果一定会是【小龙虾】吗?当然不一定,一旦变成【小汉堡】,整个模型的level就拉胯了。

其根本原因是递归问题都存在长程依赖和局部最优问题。
- 长程依赖:RNN是递归求解的序列模型,因此当序列(本文我们就单指文本序列)足够长的时候,最开始的几个字就可能会被遗忘,因此不构成训练的依赖。就比如你还记得这篇文章的最开始是那几个字吗?所以,再回头看安娜·卡列尼娜的那个文本生成模型,长句基本都是很拉胯。
- 局部最优问题:我们以【麻辣小龙虾】为例,对于【麻辣小】这三个字来说,【龙虾】是他的最优解,因为【麻辣小】+【龙虾】构成了我们爱吃的麻辣小龙虾。但是对于【小】这个字来说,有可能【汉堡】是他的最优解,毕竟曾经的小汉堡几乎全网尽人皆知。。。但是【麻辣小汉堡】就有点意义不明。这个例子就是说,如果模型每一次都选择它所认为的“最优解”,最终有可能每一步的选择都是“正确”的,但得到的结果却是错误的。
虽然我们可以用Beam-Search来解决搜索问题,但beam-search只能说是缓解了局部最优的问题(因为自然语言并不是一个最优化的问题,但目前来看我们很难找到其他的解决方案,所以我们就需要先解决局部最优化的问题)。顺着这个思路,我们也可以加长RNN的长度和深度,毕竟大力出奇迹。
其实,写到这里的时候我就突然想起来我国科学家当年试东风1号导弹,(忘记了什么原因)导致航程不够,无法在靶点爆炸。当时的大部分方案都是加入更多的燃料,但这又会增加弹体重量,那不就飞不动了吗。唯独一个年轻人的方案是抽出燃料,理论上也确实可行(大佬就是大佬)。最后还真的成功了。
所以,考虑到beam-search和大力出奇迹的方案都是增加计算量,我们可以反向思考,比如用mask的方法盖住几个词。这个方法苏神已经帮我们做了,可以去看他的博客。
我们到底在干什么?
说了这么多,我们到底在解决什么问题?
继续观察这个公式:
只看右边:
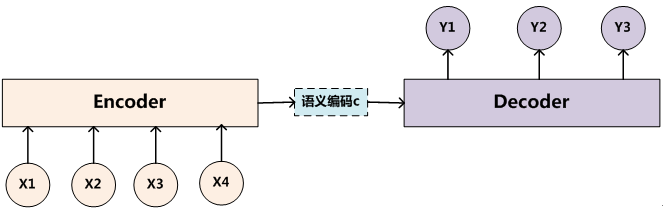
每一个$p(\cdot)$都代表着一个字,如果将这些字看做节点,实际上我们就是在寻找一个“最优”的路径把他们都链接起来。当然了,如果你回过头去看这张图:
就会发现,“桥梁”只有一条。
众所周知,一条路只能链接两个城市。如果写成公式,那就是:
$p(z)$就是神经网络所要拟合的参数之一(对应于上图的“语义编码c”),它告诉了句子应该以什么样的概率转移为另一个概率。
单一的$p(z)$显然是不充分的,【马】这个字显然是不能以相同的概率转移为马冬梅或者马化腾或者马云。
所以,为了造更多的“桥”:
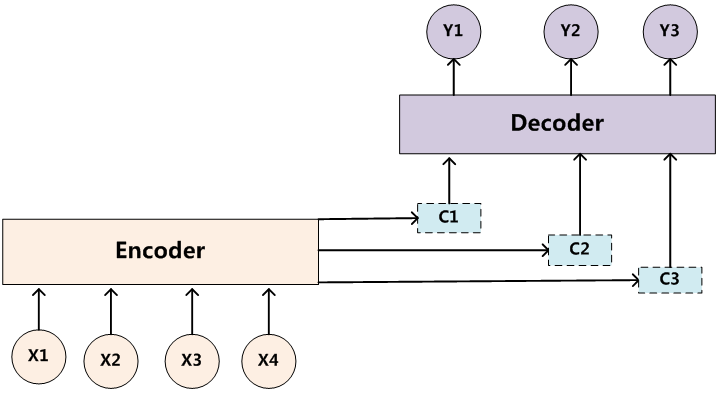
注意力机制就应运而生了。
注意力机制
其中的QKV同一个东西的三种投影。所以,如果不看softmax一项,整个公式实际上是在求非归一化的联合概率分布。
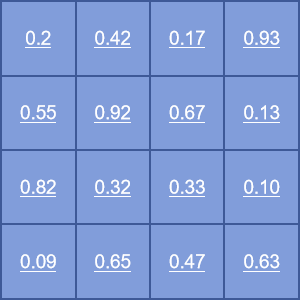
假设上图就是self attention的计算结果,每一行每一列的和都不是1,所以没有归一化。但从感觉上来看,这东西长的可真的像联合分布的计算结果啊!我们随便上网找一张联合分布的图片:
简直神似啊!
仔细一想…好像又绕回了最初的原点。
我们来分析一下:
- 早期的NLP探索者们用n元语法模型去求解联合分布,但是受制于当时的硬件条件,所以n元语法模型的探索也都止步在个位数。
- 后来出现了word2vec,滑动窗口实际上相当于n元语法中的n,但窗口大小依旧没有突破个位数。
- 神经网络大行其道,RNN递归求解条件概率,直逼联合分布。
但是随着seq2seq问题的研究(主要是当年研究自动翻译的那些学者,著名的attention公式就是从Transformer的研究中诞生的),大家突然发现,直接用attention去求联合分布不就OJBK了吗???
然后就出现了不讲武德的BERT,虽然算法层面没有太多的进步,但是从深度学习的哲学水平上来看,这波BERT在大气层。(一部分算法工程师的梦想是用数学的方法去解决复杂的问题,但是另外一批算法工程师直接对复杂问题重拳出击)

mask方法:建造跨海大桥
我们知道,自然语言是有其结构信息的,而问题在于我们对自然语言的结构知之甚少。从小学开始我们就要一直学习语法,定语从句,倒装句之类;将语法结构应用于自然语言处理也确实是NLP的最初之路。但这种路子很快就被证明是走不通的,因为我们不知道如何描述结构。反观BERT的成功,再怎么成功,其数学基础也是建立在统计学之上的,至少我们知道联合概率分布是如何计算的。现在的问题是,我们既不知道结构如何描述,也不知道结构如何计算。
所以,mask是一种通过表象去计算自然语言结构的主要方式。mask虽然被称为掩码,但其主要的功能是【补全】,就好像英语考试中的完形填空,在补全句子信息的过程之中也学习到了句子的整体结构,做的多了,自然而然的也就形成了“语感”。这个语感,实际上就是脑子里对自然语言结构的建模。在之前的叙述中,我们所关注的都是单个句子的联合分布。秉承深度学习的哲学,我们可以用mask的方式对多个句子重拳出击,甚至说如果你开心(有显卡),你也可以同时对多篇文章一起重拳出击。
具体做法就是把多个句子当成一个句子,每一个句子的句尾加入一个特殊的标记,比如$[cut]$,然后多个句子顺序拼接,直接输入神经网络进行计算。
GAN
gan的主要问题是:
- 训练困难,有可能因为梯度爆炸而导致模式崩塌。(这个训练困难的问题我不确定还是否存在,因为看到的论文是在18年发表的,而18年的时候又提出了f-gan,其中的共轭算法已经基本避免了这个问题)
- 多样性不足:具体表现为GAN文本生成模型总是会生成一些短小的句子,从而可以获得更高的分数。(但这个问题我感觉也已经基本解决了,那就是依靠mask方法做长文本输入。)
强化学习
强化学习目前给我的感觉仍旧是牛刀杀鸡。我们来简单的讨论一下强化学习中的两个概念:收益和动作空间。(这两个问题也许是强化学习在自然语言处理方面效果不显著的主要原因)
首先,收益相当于深度学习中的损失函数,因为在数学上,前者是求最大值,后者是求最小值,没有本质上的区别。对我来说,也许不同的概念会帮助人们产生不同的理解,但这种名称上的改变并没有给算法带来本质上的不同:因此我就可以在损失函数前面加上一个符号,然后将这个负损失定义为收益。
其次,动作空间。这个东西就有点像几十年前人们精心设计的特征一样。如果是对于一些简单问题,那当然是非常有效;但对于自然语言这种极其复杂的问题来说,动作空间就显得有点“狭小且破碎”,因为人工定义的动作空间目前还不能完全描述自然语言。反向思考,如果动作空间能够几乎完整的描述自然语言的特性,那我为什么不去手工写正则表达式呢?
文本生成的关键在于MASK
用mask来取代动作空间
着手建模
依旧是基于公式:
个人认为,这个是最好的文本建模方法了,公式中既包含了结构信息(贝叶斯全概率公式)又能够体现语义信息(条件概率),是非常好的生成模型。
但是好东西也是不容易获得的,条件概率的计算量可以达到无穷,力大砖飞的BERT系列甚至就可以看做一个非常强悍的条件概率计算模型。如何降低条件概率的计算复杂度问题仍旧是一个非常值得研究的问题。
好了,言归正传。首先给定一个$sentence$作为输入
文献时间
第一篇
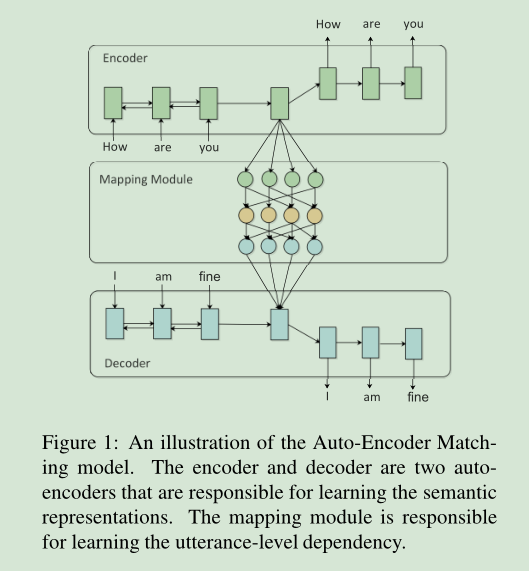
编码器和解码器都是LSTM,作者希望在隐变量空间中将上文信息与下文信息对齐,如大图中的中间那一层所示。
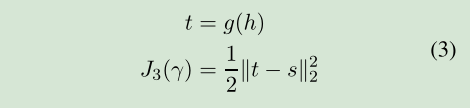
对齐的方式是L2范数。其实改成别的散度也是可以的。

生成效果如图所示。
第二篇
CommonGen: A Constrained Text Generation Challenge for Generative Commonsense Reasoning
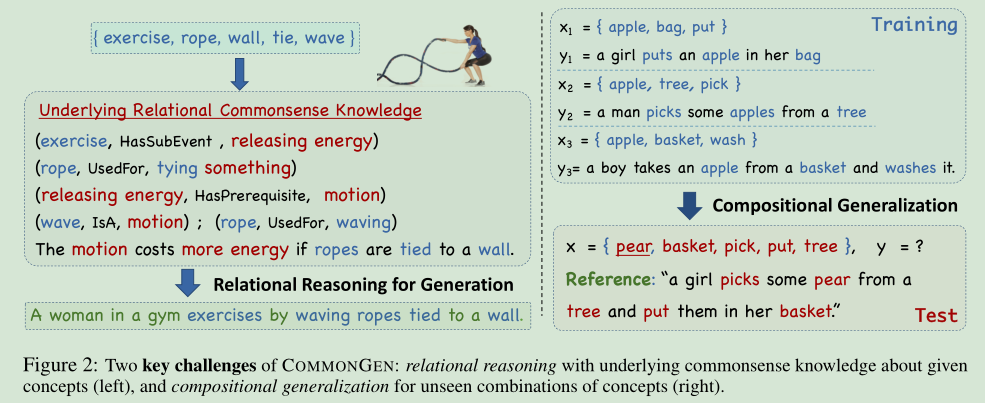
这篇文章在文本生成的任务中引入了人类的常识。
其作用相当于引入了知识图谱,这就相当于在求联合分布的时候给定了一些标签,标签相当于条件,在某种程度上相当于求解条件分布。虽然文章的任务是做图片描述,但有一些地方还是值得我们参考的。 给定的输入为若干个单词,目标是生成一句通顺的人话。 作者认为完成这个任务的条件主要有两个: 1. 词与词之间的关系 2. 合理的语法 作者首先构造了一个“概念的集合”,这个集合中的概念都是一些基本的名词和动词: $$\{c_1,c_2,...\} \in \mathcal{X}$$ 以及一个句子集合$\mathcal{Y}$,里面装的都是人话。模型的目的就是去学习$\mathcal{X} \rightarrow \mathcal{Y}$的映射。 那么这个映射应该怎么去学习呢? ***对比学习 *** 首先我们构造训练集$\mathcal{T}$,$\mathcal{T}$是$\mathcal{Y}$的一个子集,但是我们需要给$\mathcal{T}$加上一个限制条件:所有的$\mathcal{T}$ 都必须包含$\mathcal{X}$中的若干个元素举例来说(本节第一张图片所示),训练集可以长成这个样子:
x1 : {苹果,袋子,放}
t1 :{一个女孩儿把苹果放在她的袋子里}
x2 :{苹果,树,摘}
t2 :{一个男人从树上摘了一些苹果}
x3 : {苹果,篮子,洗}
t3 :{一个男孩从篮子里拿了几个苹果去洗}
好了,现在我们有了三个训练样本。里面包含了实体,以及隐藏在句子中的实体关系。在训练阶段,假设输入的概念集合为:{梨,袋子,放},【梨】这个词在训练集中从来没有出现过,那么就可以认为【鸭梨】=【苹果】,在{袋子,放}的条件下
第三篇
Adversarial Ranking for Language Generation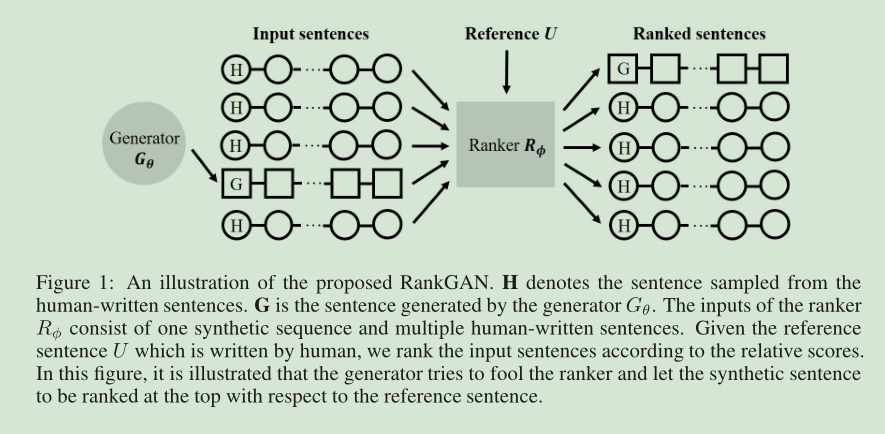
图中,G是生成器生成的文本,H是人话。RANKER是一个打分器,给所有的输入样本打分,本质上是一个discriminator.打分方法本质上还是对比学习的方法,请参考第二篇。
具体的做法是,针对相同的$x \in \mathcal{X}$,挑选出一些包含x的人话H,然后用这些x生成样本G,将${H,G}$输入到打分器中排序,并根据排序来设计loss.
第四篇
Generating Text through Adversarial Training using Skip-Thought Vectors
文本是离散的,所以不适合用GAN来训练。虽然我们可以用嵌入的方式得到词向量,但在输出端还是需要把词向量转化成离散的字,这样才能得到一句文本。就比如我们假设”你好”=1.0,但是”1.01”是什么,谁也不知道。
所以本文作者打算用稠密的句向量来做。所谓的稠密就是连续,与离散相对的概念。
在介绍这篇文章之前,我们要先看看什么是Skip-Thought。
一种传统的句表示学习方法——Skip-Thought Vectors
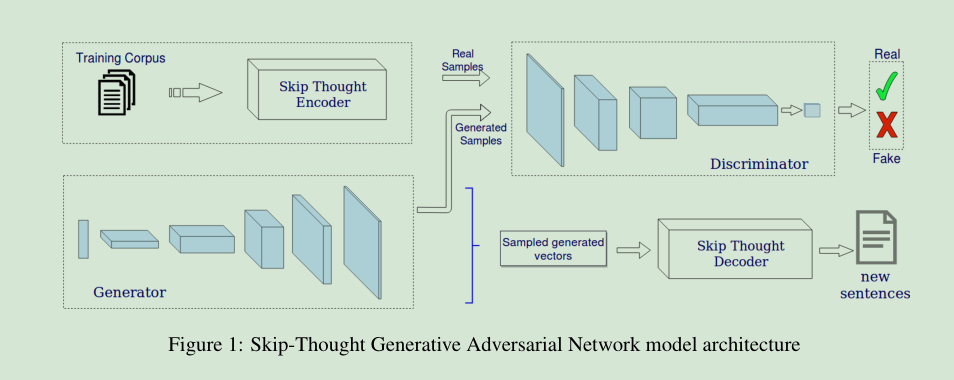
然后,原文作者将文本转化为稠密的句向量输入到GAN中做训练,输出的稠密向量用Skip-Thought 的解码器解码一下就是句子了。
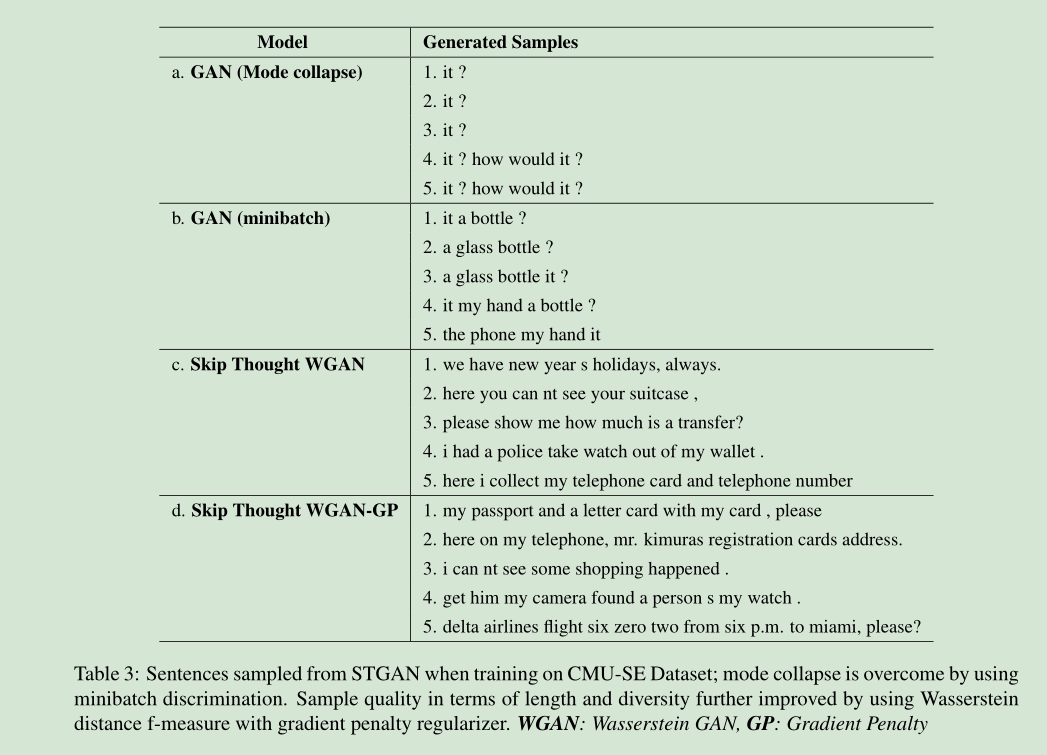
第五篇
Learning Neural Templates for Text Generation
这篇文章虽然是说用神经网络学习模板,但实际上已经是在践行强化学习了。如果将模板想象成动作空间,那就容易理解一些了。
第六篇
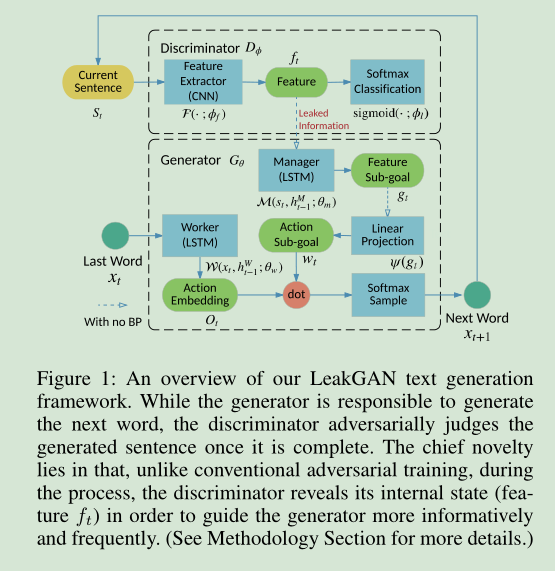
Long Text Generation via Adversarial Training with Leaked Information
文章作者认为,训练GAN的时候,目标文本序列作为控制信号是处于最后一个阶段的,而生成器所生成的隐变量序列中是包含结构信息和语义信息的,而控制信号作为离散的序列只是在最后阶段与隐变量交互信息。什么意思,就是说稠密的隐变量只有在argmax运算之后才能与文本计算距离,而argmax却大量的损耗了隐变量所蕴含的信息。
那么作者做了一件什么什么事情呢?那就是把控制序列的最后一个信号,也就是文本的最后一个字作为额外的输入信息,以及判别器的编码,输入生成器中,。
一般的GAN,生成器和判别器之间只有在BP阶段才有信息交互。
模型整体结构如下图所示。