在数据集降噪方面
GAN
DSGAN: Generative Adversarial Training for Distant SupervisionRelation Extraction
原文对训练数据的描述:
已知训练数据中含有错误的数据(红叉)、真实正确的数据(蓝圈)、假阳性数据即噪声数据(黄三角),其中真实正确的数据和假阳性数据在训练开始都被认为是“正确”数据(“positive” data),模型的假设前提是真实正确的数据在正确数据中占据的比例较大。
这篇文章是想用GAN去做降噪处理,论文给出的示意图如下所示:
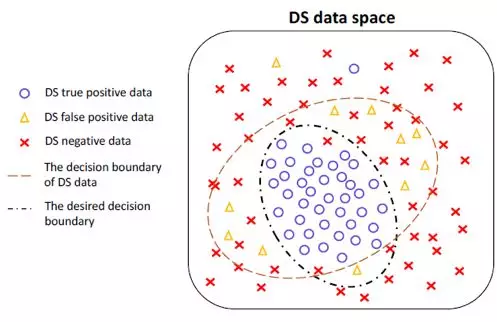
但是在现实中很难找到如此有规律的数据集,圆圈和圆圈在一起,叉叉和叉叉在一起,因为如果能达到图片中的示例效果,那么理论上用聚类也是可以的。另外,原文中的优化目标只是min-max公式,该公式的推导过程中并没有讨论“分布之间的距离”的问题。那么按照对图片描述的理解,正样本和噪声之间应该是有着不同的概率分布,那么如何去衡量两个分布之间的差异呢?用GAN直接做?那为什么不用高斯聚类。

上述这篇文章就是搞了个聚类,提升了一些性能。
但不可否认的是,研究的路上还是失败居多,总归要有人去试错去踩坑,他们探索性的工作是值得人们肯定的。
RL
另外是强化学习,哪里那么多的监督样本去学习呢?
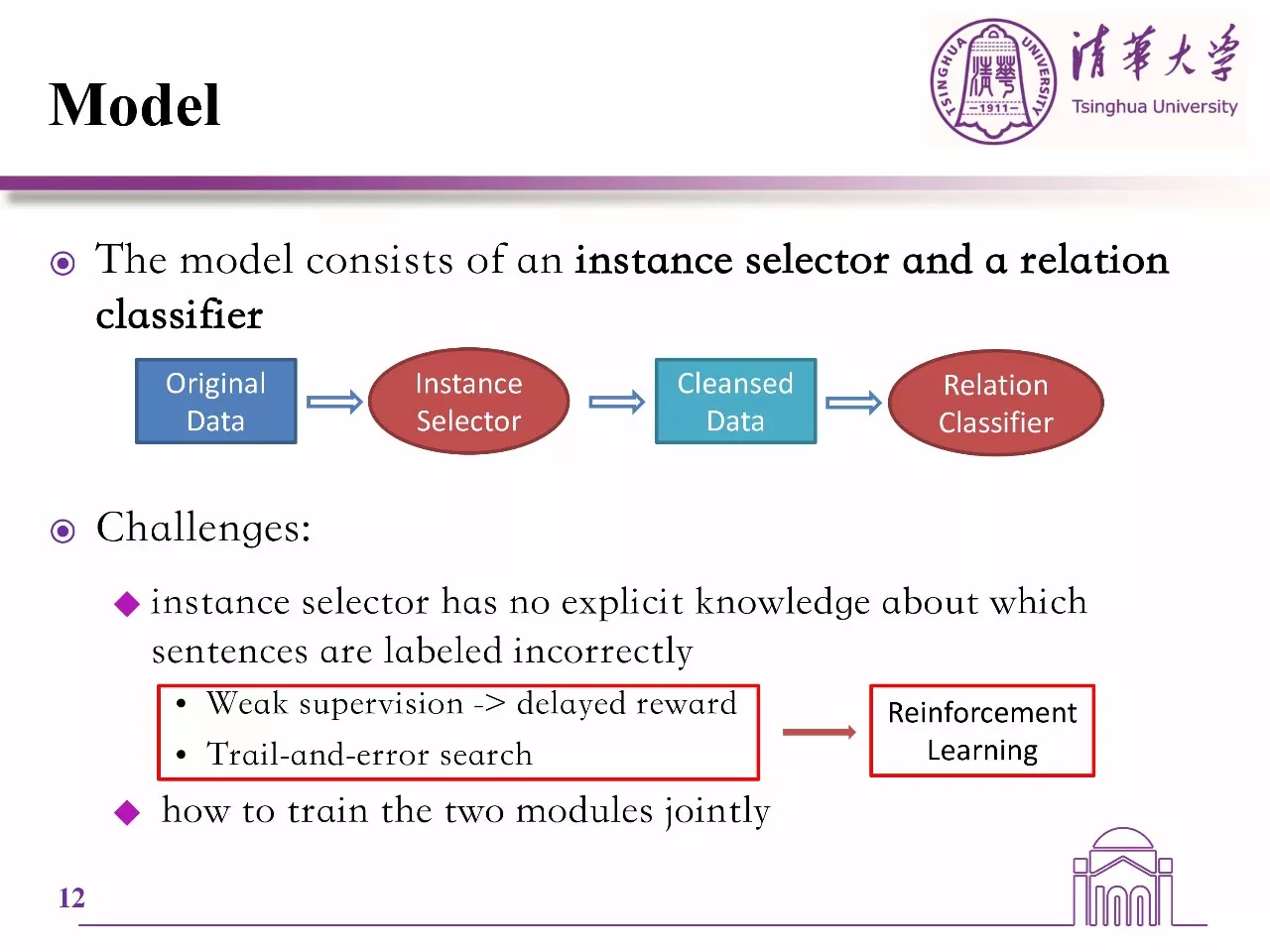
我原本是认为强化学习没法做降噪的,但是突然看到了这篇文章:

原文链接
链接2
与以往研究成果中直接移除假正例的操作不同,该策略则将这些假正例重新分配至相应关系类型的负例实例集中。文章在实验中,将使用该框架的模型的性能同当前最先进的几种模型进行了对比。结果显示,文章提出的框架能给远程监督关系抽取模型带来明显的性能提升。
最后的实验结果也表明,加入了RL能够显著提升模型的性能。但个人认为,这会急剧提升计算量。因为这个RL框架可以看成是一个“深度二分搜索模型”,我们知道,理论上二分搜索的最优复杂度是$nlog(n)$,假设一个关系抽取模型的复杂度是$k$,那么整体的复杂度就是$k\cdot nlog(n)$。
Boostsrap
微信文章
船新的标注方法
一个比较经典的文章,源自中科院,给我一种黑客的感觉,既然正面战场攻不下,那就选择侧面进攻。

文中给出的标注方法如下:

第一个标签是“O”,表示这个词属于“Other”标签,词语不在被抽取结果中。除了标签“O”以外,其他标签都由三部分组成:1)词语在实体中的位置,2)实体关系类型,3)关系角色。
论文使用“BIES”规则(B:实体起始,I:实体内部,E:实体结束,S:单一实体)去标注词语在实体中的位置信息。对于实体关系类型,则通过预先定义的关系集合确定。对于关系角色,论文使用“1”和“2”确定。一个被抽取的实体关系结果由一个三元组表示(实体 1-关系类型-实体 2)。“1”表示这个词语属于第一个实体,“2”则表示这个词语属于第二个实体。因此,标签总数是:Nt = 2*4 *|R|+1。R 是预先定义好的关系类型的数量。
青色部分是别人笔记的摘抄,从标签数量来看:
+ 2代表两种实体位置
+ 4代表标注规则一共有4种互斥的情况:BIES。
+ 1是什么没明白
模型没什么说的,但这个思想用两个字形容:牛逼。
最后是论文对于错误情况的分析:
论文认为,这是由于有大量的实体抽取后未能组成合适的实体关系对。模型仅抽取了第一个实体 1,但未能找到合适的对应实体 2,或者仅有实体 2 被正确抽取出来。
**上述问题在后来看来,主要是因为这种标注方式的每个实体只能对应于一种情况,这体现在模型抽出了两个实体但是两个实体的关系不匹配。**
**另外就是端到端的建模没有考虑先做关系分类还是先做实体抽取的问题,这就会导致识别出了句子潜在的关系,但是实体没提取出来。**
问题的解决还要到之后的
半指针-半标注方式。
---
# 图方法
另外,就目前来说还有一些基于图的方法,比较intriguing
就比如下图这个模型:
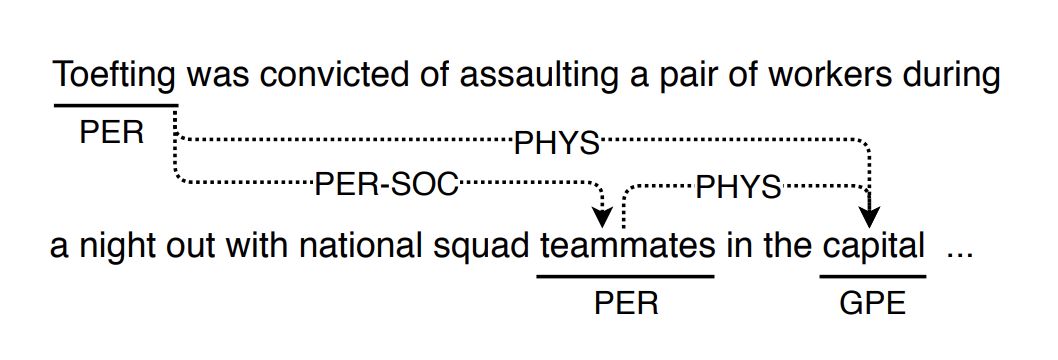
在进行关系抽取(RE)时需要同时考虑这些关联关系,借此来对实体之间的依赖关系建模。然而,现有的大多数 RE 模型在抽取关系时往往会忽略不同关系间的这种关联性。
针对这一情况,这篇文章提出了一种基于实体图的神经关系抽取模型,该模型用图的方式来表达一句话中多个实体间存在的多种关系。句子中的实体被表示为图中的节点,实体间的关系则构成图的定向边,模型用一个实体及其上下文来初始化一条边,这样,任意两个实体之间就会形成由多个边连接组成的、长度不等的多条路径。模型通过迭代的方式,将两个实体之间多条路径逐渐聚合为一条直连路径,该直连路径即对应于实体关系的最终表示。
本文的创新点和贡献主要有以下三个方面:
1. 提出一种基于路径的神经图模型,能够处理一句话中存在多种实体及多个关系的关系抽取任务;
2. 提出一种迭代算法,可以将两个实体之间多个不同长度的路径融合为一条直连路径
3. 通过实验证实,文章提出的模型在不使用任何外部句法工具的情况下,即可达到与当前最先进算法相近的性能。
又看到了一些基于句法分析的关系抽取模型。对传统方法的理解还不是很深入,但看到过网上的一些分析,句法分析往往对于长句的处理能力非常有限,这是一个问题。但对于短句来说,尤其是真实生产环境中的场景,我觉得句法分析还是会非常有用的。
写在最后
这里给出了几个比较综述的文章。
文章1
文章2
文章3